
Human and Machine Collaboration: Qualitative Decisions About Quantitative Data
This talk was originally part of a panel at the Society for Cinema and Media Studies conference in 2019.
Good afternoon, everyone. I’m John Bell, associate director of the Media Ecology Project. In addition to creating new scholarship and working with archives, MEP builds tools that support human and machine analysis of video. Today I’m going to talk through one of those tools that we prototyped a couple of years ago, the Machine Vision Search system, and think about what creating it taught us about how these tools can be used in unexpected or novel ways.
I want to start this talk with a quote I go back to pretty often:
 |
The most exciting phrase to hear in science, the one that heralds new discoveries, is not “Eureka!” (I found it!) but “That’s funny…” – Isaac Asimov (maybe) |
I’m starting with this line for two reasons.
The first is that’s it’s an important insight to keep in mind when we’re talking about using processes like machine vision or neural networks for analysis. We’re talking about computational tools that are designed to cope with massive amounts of input data, sorting through it all in a search for whatever objects, actions, or other characteristics we’re training them to look for. They’re designed to create literal moments of “I found it”–but not, notably, “hmm, that’s funny.”
The second reason I’m starting here is that, while this quote is usually attributed to Asimov, they’re not provably his words. Now, he publicly talked about similar ideas at various times, sure. But when I throw this line on a slide I should certainly be qualifying it.* My lack of 100% confidence doesn’t make the quote any less useful in this context, I just need to tell you that someone may have just made it up in the late 80’s. We, as humans, understand that contextualization can make a statement of questionable truth interesting or insightful. That complication of concrete truth, and where we’ve been running into it as we develop machine analysis software for video, is what I’m going to be talking about.
So first, some background. I’m part of a team that included Dartmouth’s Media Ecology Project and Visual Learning Group, the DALI Lab, the VEMI Lab at the University of Maine, and the Internet Archive. We received funding from the Knight Foundation to create a prototype Machine Vision Search tool. The idea behind this was to create an application that libraries, archives, and museums could use to search their collections of digital video for arbitrary objects and actions, generate tags that identified when and where in a video those search targets were found, and compile that metadata to allow fast searches based on text keywords. It wouldn’t be searching in real time, but it would allow searches for common terms to be cached for quick indexing and then provide a slower mode where it would train new classifiers on demand and send the user results later.* The user would then be given an interface where they could add their own annotations or correct the results of the automated search, which is what you see here.
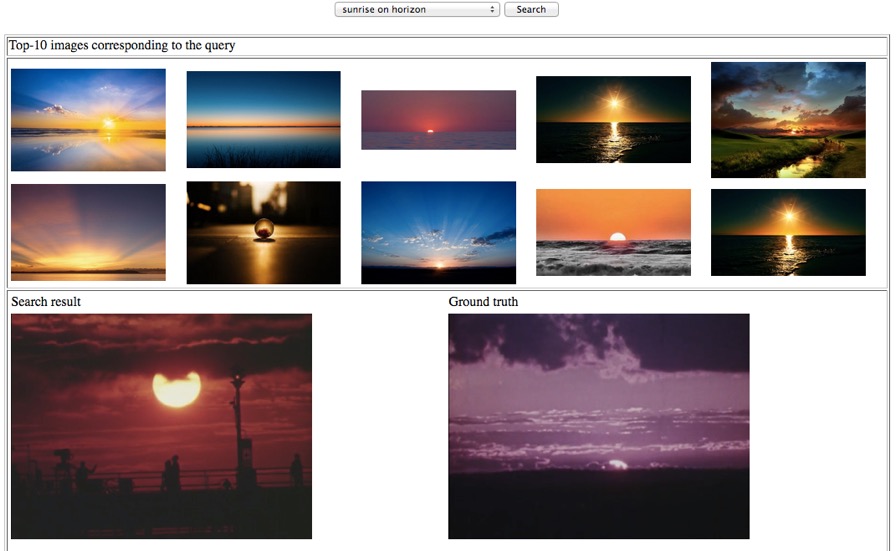
There’s an important word in that description that I kind of glossed over: arbitrary. Generally when we talk about machine learning we often talk about training an algorithm to identify specific objects or actions. We have to think in those terms because neural networks learn by association-if you want them to find a sunset you have to give them a number of images of sunsets to use as examples of ground truth. That’s why we could only provide instant search results for pre-determined terms: arbitrary terms require a new training set of data. To get around that problem, or at least, to get around that problem in our tool, we came up with a system that borrowed Google’s databases to generate ground truth on demand.
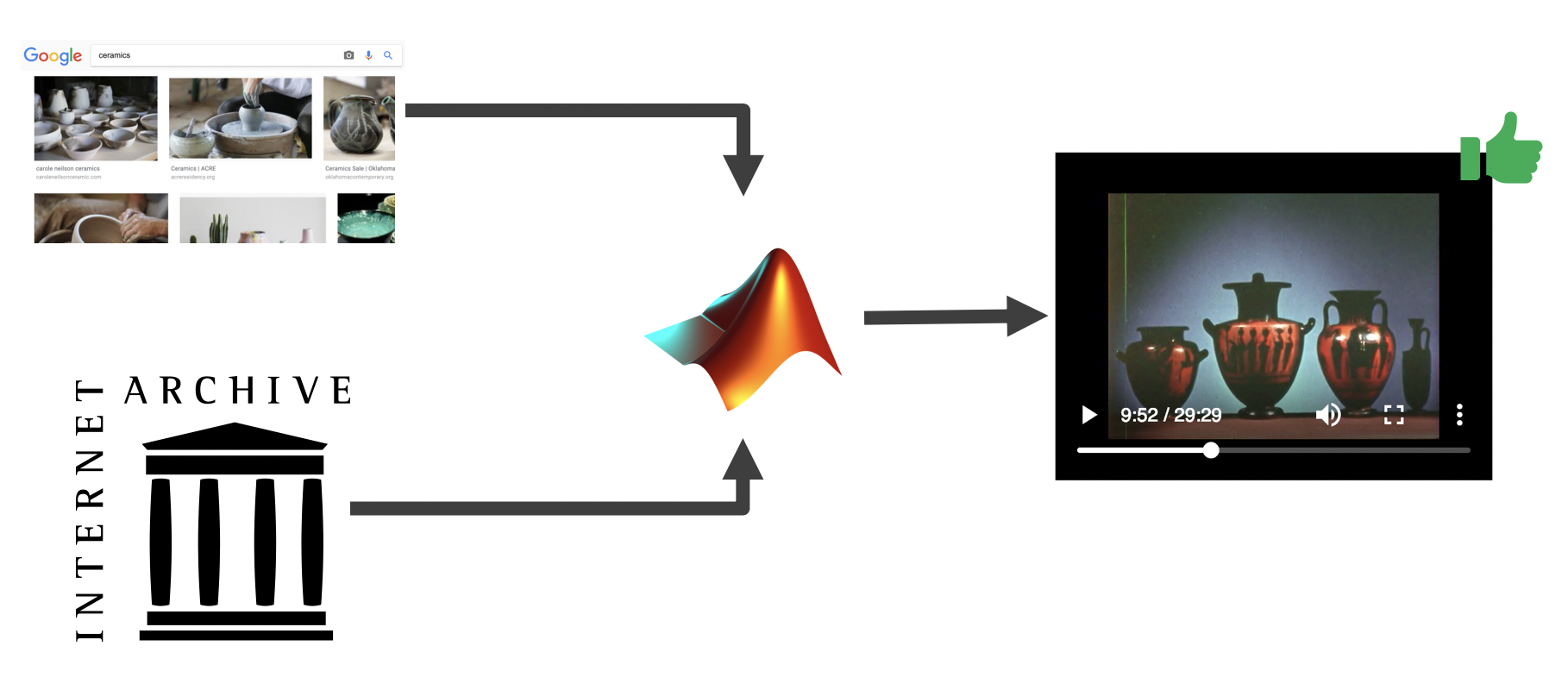
The way it works is a user types in an object or action they’re searching for, say “ceramics.” Our MVS tool sends that text to a google image search and retrieves the first hundred results it gives back.* It assumes Google knows what it’s talking about and uses those images to train an off the shelf convolutional neural network–in our case, we just used a common library in MatLab (MatConvNet) that can be custom trained. (By default, it uses a generic classifier model built from the imagenet database.)
MVS then takes the newly upgraded model, runs it across our collection of video from Internet Archive,* and spits out tags that identify when and where it thinks ceramics appears in the frame. There are definitely some limitations to this process in terms of speed and complexity, but we were happy with how it performed given that it was a prototype, largely untrained, network. In order to help refine the models further, we then created an interface that lets humans say yes, this tag is accurate, or no, it isn’t.

Even in this prototype stage, though, we were making assumptions and designing the software in ways that hid complexity from the user. For example, when I say that the neural network recognizes when a ceramic vase appears in a frame that’s hiding what the word ‘recognize’ actually means, which is that an algorithm has created a statistical score indicating how closely a particular image aligns with an abstract model it associates with the text “ceramics”.
Recognition, then, is dependent upon where we define the bounds of that score: if we the programmers say that anything above 80% confidence must be ceramics then MVS will create a tag identifying it as such. There is no qualitative in-between, only a quantitative binary output of yes, this is ceramics, or no, it isn’t. Low confidence matches are simply discarded.
Of course, all of this is done with the good intention of creating a seamless user interface. If you’re an end user then you may not care what the numbers are, you just want to know if the image you’re looking for is on the screen. But there are times when what we’re looking for isn’t a literal image but just something similar, either visually or conceptually. In that case, a seamless interface actually gets in the way.

For instance, if an artist decides she wants to find a clip of something that’s similar to ceramics, but not a literal ceramic vase, she doesn’t want to find the images with the best scores. She should be able to open up the black box and decide to only see results that have a confidence score between 20 and 50 percent.*
If she could do that, the experience of using MVS would be a seamful one, to use a word Marc Weiser coined when he was at Xerox’s PARC.
Confidence scores are only one of the important seams we ran into when developing MVS and putting its results in front of humans. In our case in particular, other points where there could be significant intervention include:
- allowing the user to choose which Google Image results they want to use as ground truth for their search
- giving editors the ability to classify a result as significant within a certain context rather than just absolutely right or wrong
- or adding a secondary layer of relationships between images that would allow users to find lateral results based on an initial search term.
All of these options start to qualify the quantitative results of the algorithm and provide opportunities for people like artists and scholars to discover more “that’s funny” results than “eureka” results, to go back to Asimov’s maybe-quote.
Now, I’ve said that like it’s easy to do. It’s not. Developers will often talk about seamless interfaces as benefiting end users, and yes, they do benefit users. But making software seamless also makes it easier for programmers like me to make assumptions that simplify writing the software. Creating seamful software forces us to increase the flexibility of everything from high level feature sets to basic data structures.
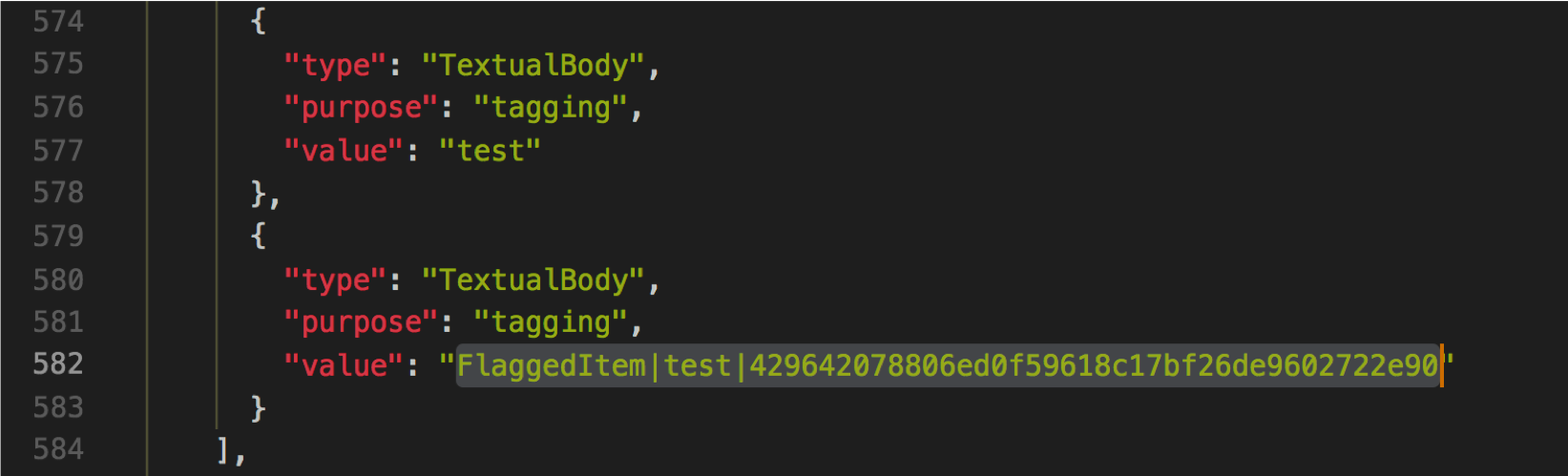
To give you an example of how pervasive these assumptions can be, when we built the validation interface that lets humans flag a machine-identified object as a false positive we used a piece of software called the Semantic Annotation Tool. Just to be clear, I’m not throwing the authors of the Semantic Annotation Tool under the bus here, not least because I’m one of them. However, SAT was built to conform to the W3C’s Web Annotation data spec.* W3C is the organization that’s nominally in charge of many standards used on the web, so their focus was on supporting marking up web resources. Web Annotation considers that you might create an annotation for time-based media and that annotation might contain a tag. What it doesn’t consider is that the tag may not be true, or that it might only be a useful tag within a specific context. There are certainly ways to make that information fit into the schema–for instance, it’s possible to annotate an annotation–but those ways require building new interpretive infrastructure that exists beyond the scope of the basic schema. For MVS, we took the quick route of just serializing multiple pieces of data–the fact that a tag was flagged as incorrect, the tag label, and the user who flagged it–into a single tag structure. It worked, but it was messy because it contradicted basic assumptions about the truth status of tags that are built into the Web Annotation spec.
I realize that this discussion of seamful vs. seamless is kind of abstract. What exposing the seams does, though, is allow you to start asking bigger questions of the software because now you have a better understanding of how it works. One of the partners I mentioned MEP working with on this project was the VEMI Lab. VEMI specializes in cognitive research on perception with a focus on adaptive technology for blind and visually impaired users. We’d previously worked with them on the Semantic Annotation Tool to make sure that its annotation playback would be compatible with screen reading software. When we started putting together the MVS prototype we had this theory that it might be useful in automatically generating tags that would help a visually impaired user understand what’s going on in a video clip, so we went back to VEMI to look at the possibilities.

In short, VEMI’s conclusion was that the data generated by our prototype object classifier wasn’t very helpful to BVI users. Issues of accuracy aside, the missing piece of data is that the objects being identified are tagged in isolation; it might be useful for catalogers to know that children appear at a particular time, but that’s not enough information for a BVI user to know what’s going on. Not all children are equivalent, it turns out.* That’s probably obvious, but what’s interesting is that the data we were filtering out as low confidence or irrelevant for search purposes was actually useful from their perspective.

For example, our classifier matched ‘painting’ with these four frames. If you look at them, you can kind of see what it saw, even if ‘painting’ isn’t the first word that would come to mind-or even accurate.
The top-left frame also matched ‘map’, and the top right and bottom left matched ‘sunrise’, but both were lower confidence than painting. Including the lower probability matches in the data starts to give a better idea of what’s going on in the frame, though it’s by no means enough information to be accurate. In this particular case you could even invert the top hits with the second ones; it makes more sense to describe those frames as a map or sunrise that looks like a painting rather than the other way around.
You can imagine, though, that opening up the classifier part of MVS to expose this otherwise discarded data would allow the creation of a description generator that understands and can convey the idea that this painting looks like a map, which might also look like fire or dancing. Now, we’re well into a form of data impressionism here, and lower the threshold for truth, the more likely you are to describe an image incorrectly. The question is what is more useful: to give information that is definitely incomplete, or to give information that might be incorrect. Trying to convey qualitative information based on quantitative data isn’t going to have the same truth status as validated quantitative data, and maybe that’s ok. In this context, it’s still at least pointing in a useful direction.

While MVS itself was a prototype, the Media Ecology Project is now exploring other ways to apply what we learned from it by mixing quantitative and qualitative annotations. Though the machine vision work is continuing, out next round of projects is looking at how humans solve the inherent interpretive problems that are highlighted by this kind of software. Our work with VEMI is continuing as one aspect of the Accessible Civil Rights Newsfilm collection, an NEH-funded project to build a collection of newsfilm from the 50s-80s focusing on the US civil rights movement. This is newsfilm that’s laden with visual context, so part of this project will be to research ways of writing annotations that can convey those impressions to someone who can’t see the newsfilm itself. Understanding how humans would construct and communicate those annotations is one step toward the contextually-aware description generator that MVS pointed us toward.

We’ve also recently launched another project to create a linked data resource describing more than 400 silent era films. The Paper Print and Biograph Compendium will put cataloging records, time-based annotations created by scholars, and machine vision-generated data into relation with one another with the goal of using each type of markup to contextualize the others.

In this compendium we’re intentionally exposing the seams between data types to help people correlate across conceptual boundaries. As with the Civil Rights project, it won’t be automating those connections yet; but it will be exposing enough data to scholars, artists, and students that they can start providing examples of how to make useful connections that we can then start building into software.
In the world of AI people often talk about those connections as turning into emergent behaviors and knowledge. We’re trying to move in a direction that encourages emergence, but our hope is that a more seamful experience will take that idea from the frankly mystical place in which its usually discussed and put the power to both understand and create emergence back into the hands of artists and scholars.
Notes
- This site seems to have done some research on the background of this quote.
- Though this paper mentions some simple examples, we actually went out of our way to find search terms to cache that wouldn’t typically appear in a keyword field with the idea that they’d prove an interesting test for finding extant ground truth.
- It’s worth noting that this method is at least somewhat eclipsed by cloud services from Amazon, Google, and others now. However, the use case of a small organization indexing mass amounts of video doesn’t fit those services well.
- We curated a set of US educational films from the 1950s-1970s as a test corpus in this study.
- This inherently will generate results that are hit and miss, and that’s ok.
- See the W3C’s annotation page.
- [citation needed]








